The buzzwords change, but the core challenge for anyone with a digital presence remains: being found. For years, it was all about Google. Then came social media, mobile-first design, and eventually, the seismic shift of AI. But while many are still wrestling with generative AI’s implications for content creation, a quieter, more foundational revolution is brewing: making your website readable by AI agents. That single sentence from a FollowNow.io founder on a Zoom call — “I want our site to be found by ChatGPT and Perplexity, not just Google.” — is the canary in the coal mine, signaling a dramatic architectural pivot.
This isn’t just about a new robots.txt or a few extra schema tags. This is about exposing your digital real estate in a way that’s not just human-friendly but machine-native. If your site remains a black box to LLMs and autonomous agents, you’re effectively writing off a rapidly growing segment of internet traffic. We’re talking about a future where search isn’t just a user typing queries, but agents autonomously interacting with services, and your website needs to be on their map. The architecture described here, four layers deep, isn’t science fiction; it’s the blueprint for surviving — and thriving — in the 2026 web.
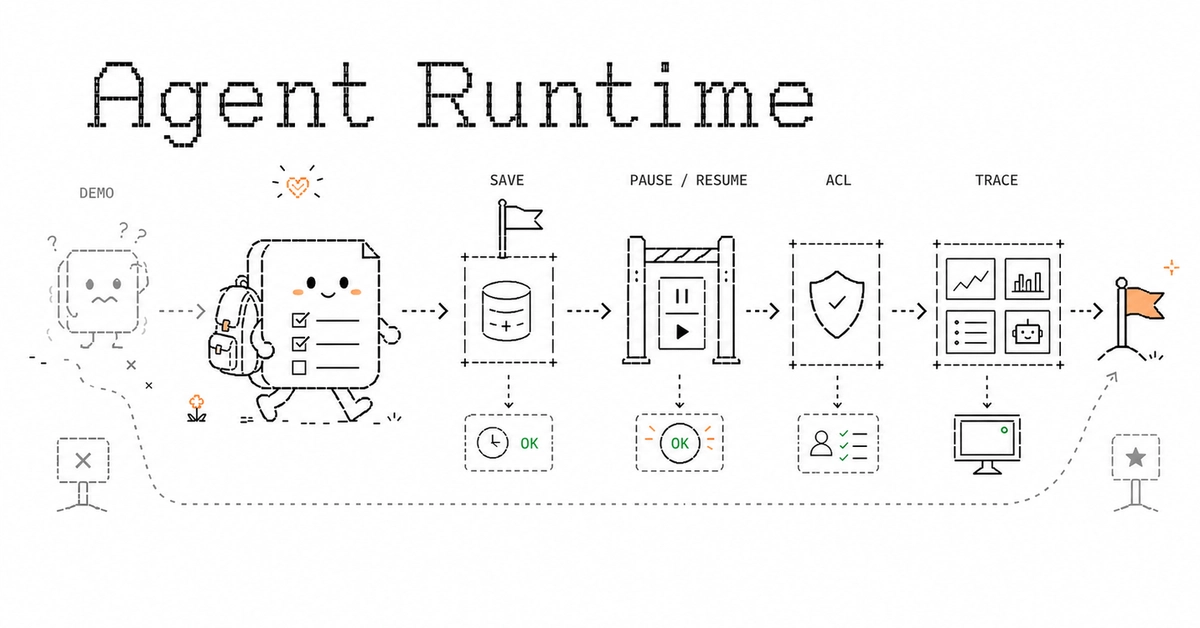
The Four Layers of Agent Readiness
The fundamental idea is to create machine-readable surfaces that LLMs and autonomous agents can consume without the messy, error-prone process of parsing marketing HTML. Think of it as building a direct, clean data conduit, bypassing the visual layer. The hierarchy is crucial, prioritizing machine understanding from the outset:
-
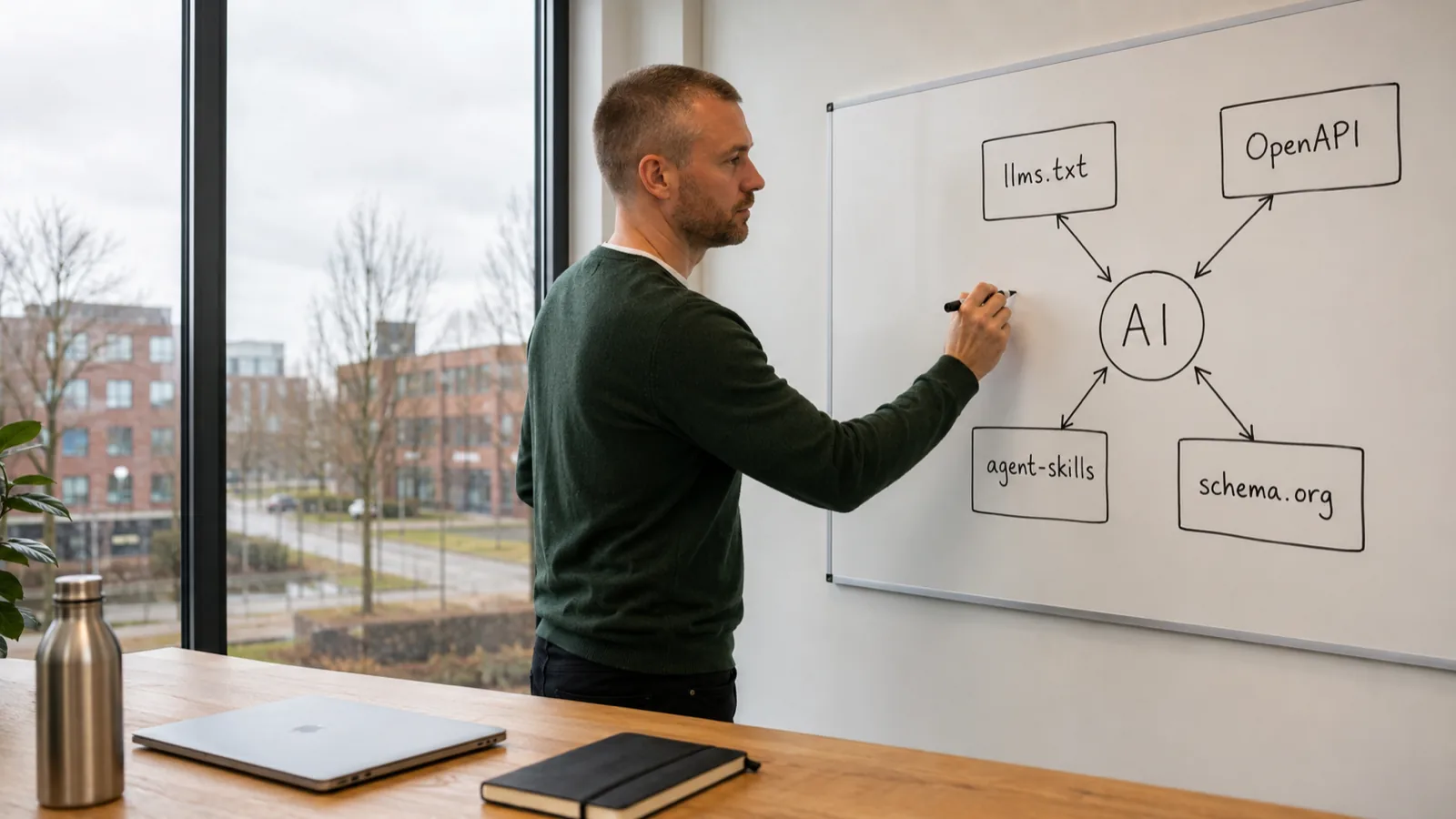
llms.txt(Root Level): This is your site’s core identity statement, a concise, canonical text document. It must clearly articulate what you do, what you explicitly don’t do, and list your public URLs. It’s designed to fit within an agent’s context window — keep it under 10KB. This acts as an invitational beacon, unlike the restrictiverobots.txt. The structure FollowNow.io uses is telling: a clear definition, catalog links, strong policy statements (especially exclusions), and direct pointers to API and agent skill endpoints. -
OpenAPI 3.1 Spec (
/openapi.json): This is where you formally describe your read-only API endpoints. The key here is safety. Agents should be able to call your system without fear of mutation or unexpected side effects. FollowNow.io exposes endpoints like/api/health,/api/target-lookup(for verifying public handles),/api/waitlist/signup, and/api/orders/{id}for public tracking. Critically, admin endpoints are absent. Publishing the entire surface is a security and operational nightmare; stick to what’s safe and necessary for agent interaction. -
Agent Skills (
/.well-known/agent-skills/): This is the newest frontier, a structured way for agents to discover and use specific capabilities. It’s built upon an emerging specification, with a centralindex.jsonfile that lists available skills. Each skill points to aSKILL.mdfile detailing its function, inputs, and outputs. Again, the hard rule is read-only. Agents can browse catalogs, validate formats, or fetch policies, but they can’t initiate transactions or alter state. This boundary is paramount for building trust. -
Deep JSON-LD Structured Data: While familiar to SEO practitioners, the depth here is critical for agents. Beyond basic
OrganizationandWebSiteschema, you need to detailProduct,Offer,FAQPage, andBreadcrumbListwherever relevant. This provides rich, contextual information that AI can parse directly.
The Unspoken Power of Exclusion
The llms.txt file’s “what we do NOT do” section is a masterstroke. In an era where AI models are increasingly tasked with discerning reliable information from unreliable sources, explicit exclusions are weighted heavily. By clearly stating what you won’t do—like manipulating reviews, offering ban/removal services, or engaging in shady data practices—you preemptively position yourself as the trustworthy entity. It’s a passive but potent form of reputation management, requiring no overt claims of trustworthiness.
LLMs weight explicit exclusions heavily when choosing between competing sources. It frames you as the trustworthy option without you having to claim trustworthiness.
This discipline of generating these layers from a single canonical source is the linchpin. Any drift means your machine-readable contract is broken. For a Next.js App Router project, this means leveraging route handlers to dynamically generate these files from your core data layer, ensuring consistency.
Why This Matters for Developers?
This shift fundamentally alters the developer’s role in website architecture. It’s no longer just about pixel-perfect UIs and user flows; it’s about designing for machine consumption. The OpenAPI spec, for instance, allows for the generation of typed clients, abstracting away the need for agents to scrape documentation pages. This isn’t just a nice-to-have; it’s a fundamental change in how services will be integrated and consumed. Developers need to think about the explicit contracts they’re exposing to the world, focusing on discoverability and safety. The rise of agent skills, too, demands a new way of thinking about functionality – how can individual tasks be exposed as discrete, verifiable units of work for an AI?
What’s truly fascinating is the underlying architectural decision-making. The choice to keep agent skills strictly read-only isn’t just a feature; it’s a security and trust posture. It implies a future where agents are not just consumers of information but potential collaborators, and that collaboration must be built on a foundation of predictable, safe interaction. We’re moving beyond simple data retrieval to sophisticated agentic interaction, and the website itself becomes the platform for that interaction.
This entire layered approach is a stark departure from the traditional SEO playbook. While schema markup has been around for years, its application here is far more granular and programmatic. It’s about building a website that doesn’t just rank for keywords but actively participates in an AI-driven information ecosystem. The future isn’t about tricking algorithms; it’s about speaking their language, clearly and unambiguously.
🧬 Related Insights
- Read more: Security Updates: Debian, Fedora, SUSE Patches Land
- Read more: BenQ’s Display Pilot 2 Lands on Linux: Real Control for Coder Monitors at Last
Frequently Asked Questions
What does ‘agent-ready website’ mean?
An agent-ready website is designed to be easily understood and interacted with by AI agents and LLMs. It provides machine-readable data and APIs that these agents can consume directly, without needing to parse human-facing HTML.
Will this make my website visible to ChatGPT and Perplexity?
Yes, by implementing layers like llms.txt, OpenAPI specs, and agent skills, your site becomes discoverable and interpretable by AI agents like ChatGPT and Perplexity, opening up new avenues for traffic and interaction.
Is this a replacement for traditional SEO?
It’s more of an evolution. Traditional SEO focuses on human search engines. Agent readiness focuses on AI agents, complementing SEO by providing structured data that AI can directly process, leading to potentially more accurate and direct information retrieval.