AI Agents: The New Foundation.
Forget shiny demos and clever prompts. The real magic — and the real challenge — for AI agents isn’t in how smart they seem, but in how reliably they can run. We’re talking about a fundamental platform shift here, folks. Think of it like going from a sleek concept car to a strong, everyday vehicle that can handle potholes, bad weather, and unexpected detours. That’s the essence of what Luhui Dev is calling the Runtime gap, and bridging it is key for anything beyond a fleeting moment of AI wonder.
Right now, we’re awash in agent demos. They’re easy to whip up: grab a model, point it at a few tools, slap on a prompt, and voilà — an agent that can search, write, and even call APIs. It’s dazzling, it’s exciting, and it’s the spark that ignites our imagination about what AI can do. But here’s the rub: a slick demo is like a beautifully choreographed dance. Production-grade AI is a marathon run through a minefield.
The Chasm Between Demo and Deployment
Once an agent steps out of the sandbox and into the messy, unpredictable arena of a business system, the game changes entirely. These agents won’t just run for a few seconds; they might churn for minutes, even tens of minutes. They’ll be wrestling with external systems, demanding user approvals, hitting network hiccups, timing out on tool calls, spitting out model outputs that drift, facing permission walls, and even dealing with mid-task interruptions from the very users they’re supposed to be serving. And oh, the state! Where was it at? What had it already asked? Which file did it write? Is that crucial conclusion still just a hypothesis? This is where the magic of prompt engineering starts to fray at the edges, and the true engineering challenge emerges.
The Real Moat: Stability, Not Just Smarts
The latest insights from LangChain, as highlighted by Dev, underscore this critical point: the real competitive advantage for business-grade AI agents isn’t found solely in optimizing prompts or building a prettier agent loop. It’s in constructing a stable foundation. This means wrestling with the unglamorous but essential aspects: state management, granular permissions, strong recovery mechanisms, insightful observability, and smoothly human collaboration. These aren’t just nice-to-haves; they are the bedrock upon which reliable AI systems are built.
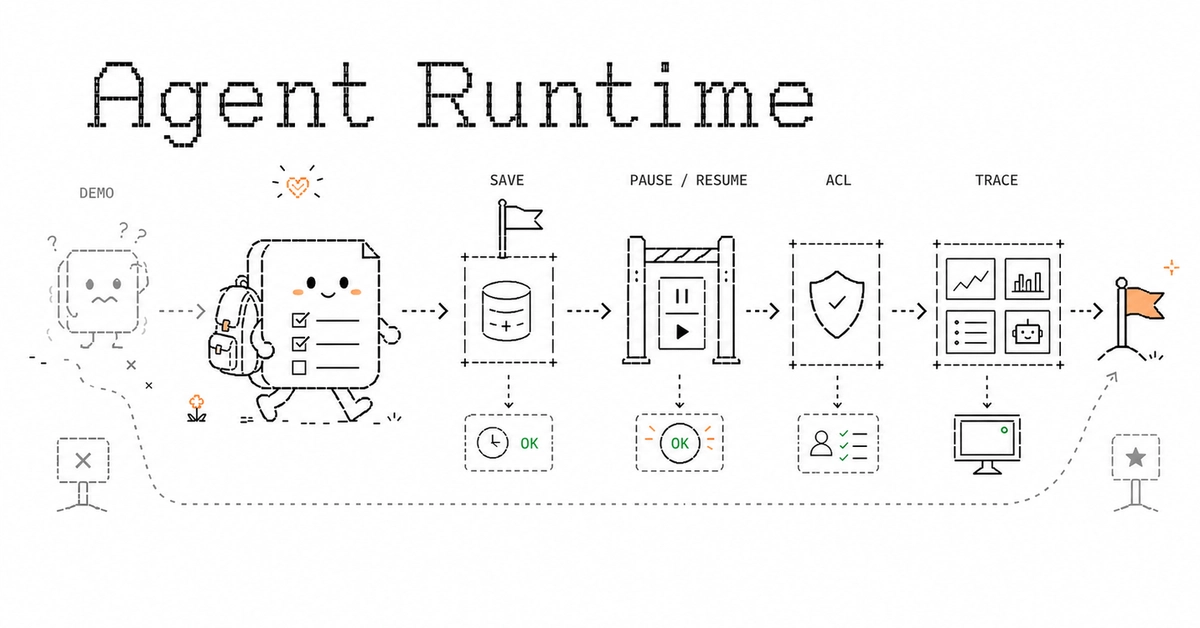
Six Pillars of Agent Reliability
When we talk about making AI agents reliable, the immediate fear is often about hallucinations – those delightful moments when an AI confidently states something completely false. And yes, that’s a significant hurdle. But in a production environment, the surface area for failure expands exponentially.
Consider this: your agent might crash on step eight of a twenty-step process. Simply re-running it isn’t just a waste of computational resources; it can lead to duplicate calls to external APIs, corrupting your data and leaving behind a tangled mess of dirty information.
What if a tool fails mid-execution? An API times out, a web page refuses to load, a database query throws an error. Without built-in retries, intelligent fallbacks, and persistent state, the entire task devolves into a high-stakes, one-shot gamble.
Then there’s the human element. An agent might patiently wait for user approval, only for the user to return an hour later. If the system can’t recall the context of that specific approval request, the entire interaction falls apart. And what about user interactions at the command layer? If the agent is mid-flight and the user decides to pivot, saying “Wait, that’s the wrong direction, let’s try plan B,” how does the system respond? Does it queue the new instruction, interrupt the current flow, restart everything, or flat-out reject it? Without a clear, predefined policy, the user experience disintegrates.
So, reliability for a production agent isn’t a single attribute. It’s a mosaic of at least six key areas: execution reliability, state reliability, interaction reliability, permission reliability, observability, and operational reliability. The true value of a dedicated Runtime is its ability to package and formalize these solutions, saving every development team from the Sisyphean task of reinventing the wheel.
Harness vs. Runtime: A Crucial Distinction
It’s vital to distinguish between an Agent’s Harness and its Runtime. Think of the Harness as the agent’s persona and intelligence layer. It dictates how tasks are planned, how prompts are crafted, which tools are at its disposal, whether it spawns sub-tasks, its access to a filesystem, its use of sub-agents, and how it compresses context. This is the layer that directly influences how “smart” the agent appears.
The Runtime, on the other hand, is the engine beneath the hood. It’s responsible for the gritty details of how agents are executed, persisted, recovered, interrupted, observed, scheduled, isolated across users, and how concurrent requests are managed. This is the layer that determines whether the agent can actually serve as the backbone of a business system.
Too often, in the rush to create impressive open-source agents, these crucial runtime concerns get shoehorned into the harness. Rules are crammed into prompts, try-catch blocks proliferate within tool calls, state management is bolted onto a database haphazardly, and a simple loading spinner becomes the extent of frontend observability. It might work in the short term, but over time, it inevitably devolves into an unmaintainable tangle of logic. LangChain’s Runtime approach elegantly sidesteps this by abstracting these cross-cutting capabilities out of the immediate agent loop context.
The Power of Durable Execution
If there’s one single design principle from LangChain’s Runtime approach that stands out, it’s the concept of durable execution. Most conventional web requests are fleeting: a request comes in, some work is done, a response is sent, and it’s over. Agents, particularly in business contexts, operate on a different timescale. They might embark on multi-step journeys: understanding a task, dissecting it, fetching information, calling various tools, creating intermediate files, pausing for human consent, continuing the process, and finally generating a comprehensive report. This naturally spans multiple model inferences, tool invocations, and user interactions.
When tasks get long, the system has to answer one question: what if it crashes in the middle? LangChain/LangGraph’s answer is checkpointing. Key states during execution are continuously persisted. On recovery, you don’t start from scratch — you resume from the most recent reasonable state.
The critical question for any long-running process is: what happens if it crashes mid-stride? LangChain and LangGraph offer a compelling answer: checkpointing. Key states within the execution are constantly saved. When a crash occurs, the system doesn’t have to begin anew from square one; it can smoothly resume from the most recently saved, stable state. For any business system, this isn’t merely a cost-saving measure; it’s the very mechanism that prevents disastrous side effects from duplicate operations.
How it Works: State Graphs and Checkpoints
At its core, LangGraph models agent execution as a state graph. Each node in this graph represents a distinct step or state in the agent’s workflow. When the agent progresses from one state to the next – perhaps after completing a tool call or receiving user input – this transition is captured. The crucial innovation lies in how these states are persisted. Instead of relying on ephemeral memory, critical intermediate states are written to durable storage. This means that even if the entire process is abruptly terminated – due to a server reboot, a network failure, or an application crash – the agent’s progress is not lost.
Upon restart, the system consults the durable storage, identifies the last successfully persisted state, and resumes execution from that point. This checkpointing mechanism is the backbone of durable execution. It ensures that complex, multi-stage tasks can be handled with a resilience previously only found in traditional enterprise software, bringing a much-needed layer of stability to the dynamic world of AI agents.
This isn’t just about avoiding lost work; it’s about the predictability and reliability required for commercial adoption. A system that can recover from failures without creating data inconsistencies or requiring manual intervention is a system that businesses can trust and integrate deeply into their operations. The runtime, in this light, is not just an execution environment; it’s a promise of stability and continuity in the often chaotic early days of AI agent deployment. The ability to checkpoint and resume is what transforms a fascinating experiment into a dependable tool.
Why This Matters for Developers
The implications for developers are profound. Instead of building ad-hoc error handling and state persistence into every single agent project, developers can use a standardized runtime that handles these complexities. This frees up cognitive bandwidth to focus on the agent’s core logic, its intelligence, and its unique capabilities. It means faster iteration cycles, more strong deployments, and ultimately, more successful AI-powered products reaching the market. The infrastructure for reliable agents is starting to solidify, and understanding these underlying principles is becoming paramount for anyone building in this space.
Common Pitfalls and the Runtime Solution
The common pitfalls Dev highlights – crashing processes, failing tools, lost context during human approval, and chaotic interaction layers – are precisely the kinds of issues that a well-designed runtime is built to address. For instance, a runtime can implement sophisticated retry strategies for tool calls, ensuring that transient errors don’t derail the entire process. It can manage the lifecycle of user approvals, maintaining context and state even during extended waiting periods. And it can provide a structured framework for handling user interruptions, allowing for graceful rollbacks or plan adjustments rather than outright failure.
By abstracting these concerns into the runtime, developers are provided with a powerful toolkit. They don’t need to be experts in distributed systems or state management to build reliable agents. They can rely on the runtime to provide that foundational stability, allowing them to innovate on the agent’s behavior and intelligence. This shift democratizes the ability to build production-ready AI agents, lowering the barrier to entry and accelerating the pace of innovation across the industry.
🧬 Related Insights
- Read more: Fedora’s All-Open-Source Virtual Summit: The Stack That Actually Worked
- Read more: MCP in 2026: AI’s USB-C Finally Lands, But Watch for the Fine Print
Frequently Asked Questions
What does LangChain Runtime actually do? LangChain Runtime provides the underlying infrastructure for running AI agents reliably in production. It focuses on aspects like durable execution, state persistence, recovery from crashes, and managing interruptions, ensuring complex agent tasks can be completed without data loss or system failure.
Will this make AI agents stop hallucinating? A strong runtime like LangChain’s is primarily focused on the execution and reliability of agents, not directly on stopping model hallucinations. While it can help recover from errors and manage states, addressing hallucinations typically requires improvements in the underlying LLMs, prompt engineering, and retrieval augmentation techniques.
Is this different from a simple AI chatbot framework? Yes, significantly. While frameworks might handle basic conversation flows, a production-grade runtime is designed for complex, long-running, stateful, and interruptible workloads. It addresses challenges like process crashes, API failures, and maintaining context over extended periods, which are beyond the scope of typical chatbot frameworks.



