The hum of a cooling fan was the only sound in the dimly lit room, a stark contrast to the whirlwind of potential that AI coding assistants promised.
When coding gets 10x faster but review, CI, and release don’t budge, you don’t get 10x delivery. You get a longer queue behind the keyboard. And if your stack includes a database layer, that queue often shows up twice — once in application CI, again in migrations, backups, and failover. This is the quiet crisis many engineering teams are facing.
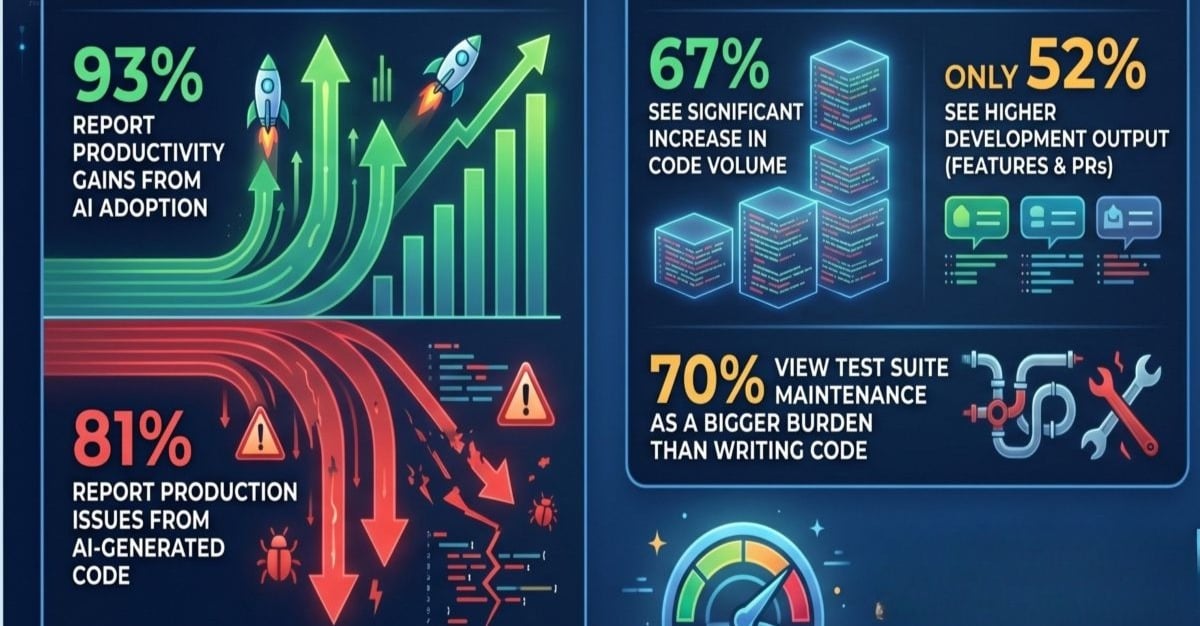
I’ve been following the discourse around AI-driven software development with a healthy dose of skepticism. Lots of teams are now clamoring about delivery being 10x or 50x faster with AI tools. It’s an alluring narrative, certainly, but one that glosses over a fundamental truth: Faster code generation is not the same thing as faster software delivery.
Think about it. An agent can churn out a patch in ten minutes. Great. But whether that patch can safely land on main, be validated, reach real users, and be debugged or rolled back when it inevitably breaks—that’s a vastly different system entirely. If only the “writing code” step speeds up while review, testing, release, monitoring, and rollback remain glacial, then that supposed “50x faster” speed is often a local illusion: one part of the pipe got hot; the entire organization is still stuck in molasses.
The Real Shift: Beyond Code Generation
Most teams, in my view, haven’t hit that “quantity becomes quality” inflection point yet. The real architectural shift isn’t about “everyone running more coding agents.” It’s about how you set goals, how you verify code, how you ship features, and how you contain risk. Otherwise, AI doesn’t multiply delivery; it multiplies PRs waiting for review, features waiting for validation, and branches waiting to merge.
As CircleCI puts it, success in the AI era is “no longer determined by how fast code can be written” — the decisive factor is whether you can “validate, integrate, and recover at scale.” For most teams, that’s a much sharper, more salient framing than obsessing over whether AI can generate code at all.
What’s truly fascinating, and often overlooked, is that Cat Wu from Anthropic has stated outright that new internal models weren’t the primary driver of their faster iteration cycles. The significant lever was process — how goals are articulated, how documentation is crafted, how previews are shipped, how cross-functional work flows, and who has the ultimate authority to put something in front of users. Shipping a feature a day isn’t about the model’s coding prowess. It’s about an organization actively dismantling the historical impediments to releases.
My core thesis here is simple: When code generation becomes cheap, the truly expensive thing becomes judgment. This encompasses judgment about what’s worth building, how good is “good enough” to ship, where human oversight is absolutely essential, and where an agent can be trusted to run to completion without supervision.
So, “AI-native” speed isn’t about every engineer wielding an AI code-writing tool. It’s a dual transformation: Less idle motion in the process. More clarity in the rules.
Less idle motion means ruthlessly cutting down on the superfluous documents, handoffs, and approvals that exist solely because “that’s how we’ve always done it.” More clarity means explicitly defining goals, evidence requirements, verification procedures, permissions, release strategies, and rollback plans — not leaving them to be reinvented in every ad-hoc hallway conversation. Only when both of these conditions are met does “one release per day” stop feeling like a high-stakes gamble.
Why More PRs Aren’t Always Progress
Seeing Anthropic ship frequently, many observers jump to the conclusion: powerful models, engineers fine-tuning Claude Code, therefore rapid coding. That helps, of course, but it isn’t the central narrative. If coding is the only thing that speeds up, what’s the tangible outcome? More PRs languishing in review queues. More features stuck in validation loops. More half-finished branches gathering digital dust. Increased production risk. And, inevitably, more arguments about whether this is shippable at all.
That’s not faster delivery; it’s congestion moved downstream from the act of typing to everything that follows. A routine feature might have once taken days from conception to the first PR. Now, a crisp, well-defined small ask can generate a first diff in minutes. But “code exists” is merely a brief leg of the entire journey. Following that comes a critical chain: Should we even build this? Is this the right shape for the solution? Who owns the blast radius if something goes wrong? Is the test evidence sufficient? Can we spin up a preview environment? Should this feature be shielded behind a feature flag? What’s our rollback strategy?
When coding itself was a bottleneck, that entire chain was effectively masked by coding time. Code generated in thirty minutes, CI still taking twenty, review requiring half a day, and QA still being queued – all of that led to the backlog becoming painfully visible. This aligns with Qovery’s analysis of AI and DevOps in 2026, which posits that as AI coding tools explode code throughput, CI/CD, environment provisioning, and deployment pipelines — not typing speed — become the primary constraint. As they articulate it, the bottleneck has flipped: less time spent coding, more time spent waiting on builds, previews, and deploys.
So I’ve fundamentally stopped framing R&D efficiency solely as lines of code per hour. A more accurate metric is: AI compresses the coding segment and forces you to confront the real system bottleneck. The lesson from Anthropic’s public interviews isn’t just about having a superior model; it’s about understanding that the real gains are unlocked when the entire delivery pipeline is re-architected for speed and clarity.
As CircleCI puts it, success in the AI era is “no longer determined by how fast code can be written” — the decisive factor is whether you can “validate, integrate, and recover at scale.”
The Database Double-Dip
This phenomenon is amplified in systems with a significant database layer. The need for schema migrations, ensuring data integrity through backups, and orchestrating failover processes adds entirely new dimensions to the delivery pipeline. When application code churns faster, these database-centric operations can become secondary bottlenecks, effectively doubling the downstream queue. OceanBase’s approach, which involves deep integration and thinking about these database operational concerns holistically, is a vital part of tackling this compounded slowdown. It’s not just about the application; it’s about the entire data-serving fabric.
**
🧬 Related Insights
- Read more: Scrapy Maintainer Drops Bombs on AI Scrapers: Code’s a Breeze, Pages Fight Back
- Read more: Java’s Performance Leap: Beyond 1BRC to Native AI Development
Frequently Asked Questions**
Will AI replace developers?
AI is more likely to augment developers, handling repetitive coding tasks and freeing up human engineers to focus on higher-level design, complex problem-solving, and critical judgment calls. The emphasis is shifting from raw coding output to strategic application of engineering expertise.
How can my team speed up delivery with AI?
Focus on optimizing your entire software delivery pipeline, not just code generation. This means streamlining review processes, improving CI/CD automation, clarifying release criteria, and enhancing monitoring and rollback capabilities. AI tools should be integrated into this optimized workflow, not treated as a standalone solution.
What’s the role of judgment in AI-driven development?
Judgment is becoming paramount. AI can generate code, but humans must provide the judgment on what to build, how well it needs to be built, when to ship, and when to trust AI versus human oversight. This human judgment is the critical differentiator in an AI-accelerated development environment.