Forget the bells and whistles of the latest AI model or the promise of a new distributed database. For most real people – the players of online games, the users of mobile apps – the news that matters most is often the simplest: does it feel fast?
And that’s precisely where the wheels fell off the wagon for one engineering team, tasked with making treasure hunts in a game feel not just responsive, but instant. Marketing wanted it. The CFO signed off, seeing dollar signs in faster session revenue. The mandate? A 200 OK response before a player’s thumb even finished lifting from the screen. A laudable goal, perhaps, if it hadn’t devolved into a costly, multi-sprint engineering nightmare.
It all started with a fairly standard event bus setup. Open a chest, claim a prize – these were messages blasted out to inventory, wallet, and analytics services, each with its own database. The initial promise was atomic consistency, managed by a saga pattern with compensating transactions. The snag? This orchestrator, the linchpin of their supposed atomic guarantee, added a sluggish 80-140ms of latency under load. Worse, the marketing dashboard, blissfully unaware of the actual system strain, reported a rosy 95th percentile of 85ms, a number that only reflected the orchestrator’s completion, not the downstream services’ final nod.
So, they tried sharding by player ID. A 60% cut in the fan-out path looked promising. But then, the dreaded double-credit edge case reared its ugly head. A wallet service would confirm a claim, fire off a success event, but then tank before its analytics counterpart got the memo. The saga orchestrator, sensing a timeout, would diligently roll back the wallet update, restoring the player’s balance. Meanwhile, a separate analytics loader, operating on the assumption that the event was authoritative, had already recorded the revenue. The CFO, presented with phantom revenue spikes, had to sheepishly issue $87,000 in refunds over two weeks.
Next up: Redis Streams with consumer groups. Promising ordered processing and exactly-once semantics, this seemed like the silver bullet. They ditched the saga orchestrator entirely. And then, disaster struck during a consumer group rebalance. A mere 4.2-second window saw 1,800 duplicate chest openings because consumer offsets failed to advance atomically with acknowledgments. Their retry budget was a measly 120ms, a pittance against a backlog that grew faster than they could scale pods.
The Single-Database Solution (and Its Tradeoffs)
Ultimately, they ripped out the event bus, opting for a single database transaction that updated inventory, wallet, and analytics in one ACID block. The cost? They were now exclusively tied to PostgreSQL. Sharding the primary key by player ID meant the entire treasure hunt operation was a single UPDATE statement with a RETURNING clause. Latency plummeted to a respectable 15ms (95th percentile). But the tight coupling was a stark reminder of what they’d sacrificed: service independence. Inventory schema changes now meant wallet breakages; a new analytics column demanded a full endpoint redeployment.
Feature flags became their lifeline, a way to manage this newfound rigidity. If a flag was off, the system gracefully fell back to the older, slower event bus path. This allowed for a gradual rollout, a 14% canary group seeded by session IDs divisible by seven, just enough to catch the weird edge cases without polluting global metrics. A circuit breaker was also thrown in, ready to flip to the fallback if 500 errors spiked beyond 0.3% in a 30-second window.
Was the Pain Worth the Gain?
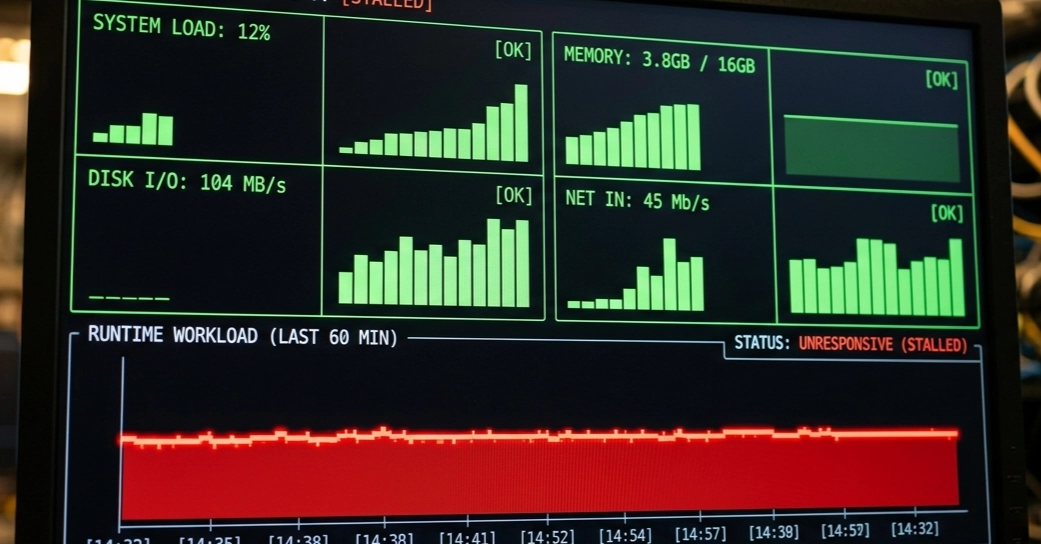
For 47 days, the new path held. No false-positive treasure awards. 95th percentile latency remained at 15ms, with 99.7% of requests completing under 50ms. Database CPU usage, predictably, spiked. A read replica in us-west-2 was added to absorb analytics reads. Then came the surprising discovery: 12% of treasure hunts were bots. By ditching the asynchronous saga pattern, they’d inadvertently closed the timing gaps that automation scripts had previously exploited for double claims.
But the operational reality bit hard. Previously, a lagging event bus meant restarting a single service. Now, a breaking inventory schema change required a full cluster redeploy. Rollback? A full database restore from an S3 snapshot, a process that took a nerve-wracking 8 minutes and 22 seconds in staging. The old saga path, a theatrical performance of speed, was relegated to the feature flag for emergencies only – the one that could be rolled back in minutes.
I would have pushed back on the sub-second requirement from day one. The psychological truth is that anything under 100ms feels instant, but anything under 200ms feels acceptable. We spent three sprints chasing a 15ms gain that only mattered to marketing dashboards. If I had insisted on measuring perceived latency—time from tap to visual feedback rather than endpoint completion—we could have saved months of engineering drama.
The author’s post-mortem is a stark reminder: chasing marketing’s perception of speed can blind engineers to more fundamental issues of reliability and operational cost. The obsession with milliseconds, when hundreds would suffice for user perception, led to the very fragility they were trying to escape. This saga serves as a potent, and expensive, case study in the perils of underestimating the complexity of distributed systems and the allure of vanity metrics. It’s a story of chasing shadows, and the very real financial penalties that come with it.
The sharded Redis Streams experiment, in hindsight, was doomed. Consumer group rebalances, the author correctly points out, are inherently non-deterministic under production load. The only streams that truly scale are those where the partition key aligns with an immutable business key – player ID, session ID. Without that guarantee, streams become a potential quagmire.
Finally, the lack of early observability. A simple metric like a treasure_latency_seconds_histogram, measuring time from tap to successful treasure claim, could have provided crucial early warnings and saved immense debugging headaches. It’s the operational equivalent of forgetting to pack a first-aid kit on a camping trip – you hope you won’t need it, but the consequences of not having it can be severe.
What this entire ordeal underscores is that sometimes, the simplest, most coupled solution—one database transaction—is the most strong, even if it sacrifices perceived architectural elegance. The market demands speed, but it also demands reliability. When those two come into conflict, it’s the engineering team that bears the brunt, and the company’s balance sheet that suffers the consequences.