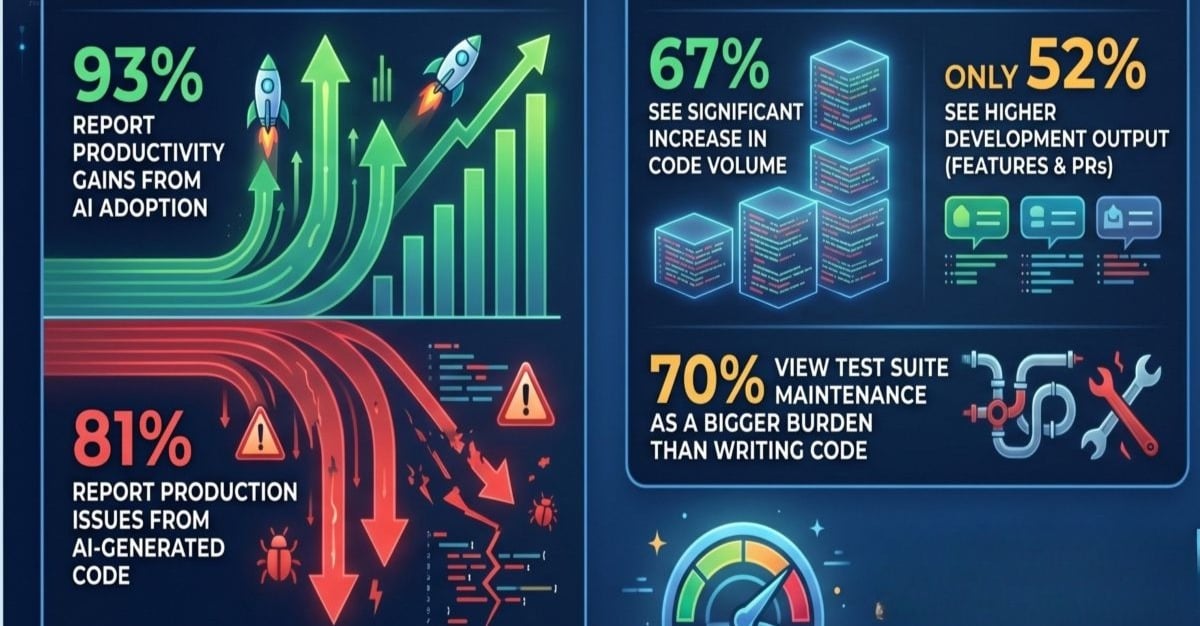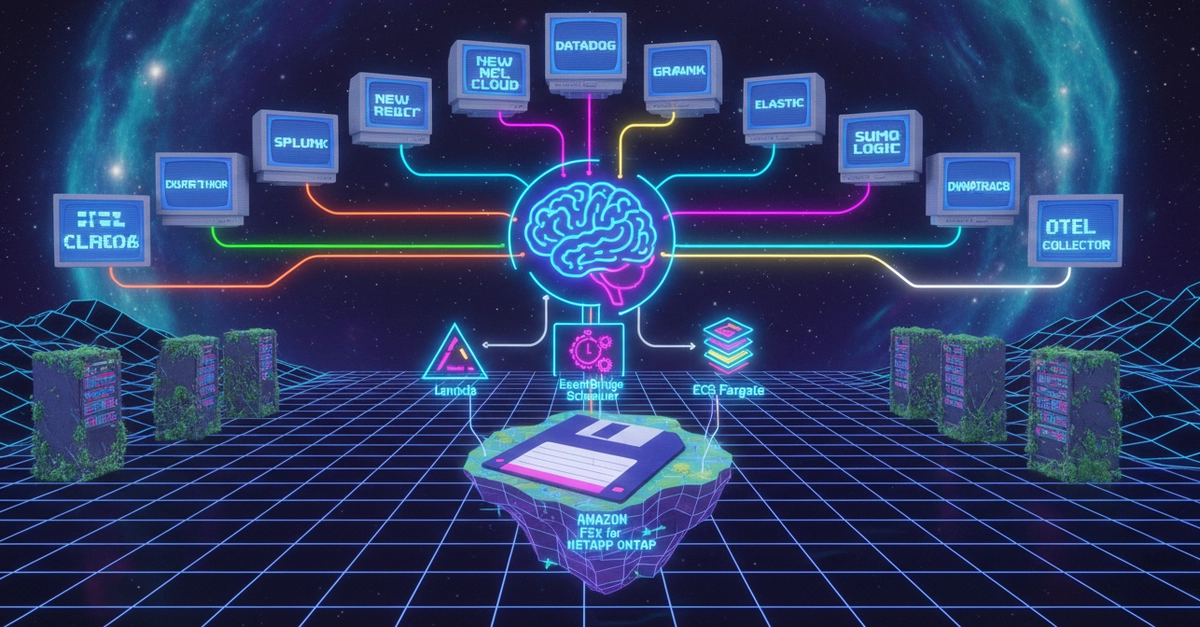
Here’s a sobering statistic for anyone building AI systems that interact with production infrastructure: 85% of AI reasoning today is based on static data. That’s code, configs, schemas, deployment definitions – a pristine, theoretical snapshot. But anyone who’s actually operated a system knows production isn’t a museum exhibit.
It’s a frantic, messy, perpetually evolving beast. Think about it: the gap between what your Terraform declares and what’s actually running in the cloud can be immense. Hotfixes, partial rollouts, deprecated services clinging to life, and those “temporary” workarounds that become permanent fixtures 11 months later. This isn’t an edge case; it’s the default operating mode.
Drift is the norm. Schemas change. Queues get repurposed. Lambda functions quietly absorb new responsibilities. Environment configurations diverge like rogue tributaries. Feature flags outlive entire product strategies. And somehow, miraculously, the whole precarious edifice continues to function, held together by institutional memory, late-night monitoring alerts, and sheer engineering anxiety.
AI systems, by and large, lack this messy context. They’re trained on the idealized, declared layer, not the chaotic, running layer. When an AI agent assumes an index exists because Terraform mentions it, or a service is healthy because it’s in a config file, it can generate confidently wrong operational decisions. The syntax might be perfect, but the underlying model of reality is stale.
Is Static Analysis Enough?
This inherent mismatch between declared and actual state is why purely static approaches will eventually hit a ceiling for infrastructure-heavy AI. Sure, better retrieval, larger context windows, repository indexing, and schema awareness all help. They’re steps in the right direction. But they don’t capture the dynamic, often irrational, evolution of production systems.
Production systems are living systems. Not snapshots.
To truly reason reliably about infrastructure, AI needs to grasp runtime state, deployment reconciliation processes, drift detection mechanisms, evolving dependencies, and operational anomalies. It needs to know what’s actually true right now, not just what was declared six months ago and might still exist.
This is a significantly harder problem than simply generating code. But it’s the problem that matters most once software scales beyond a handful of servers. The thinking behind projects like Infrawise seems to stem directly from this chasm between theoretical infrastructure definitions and the messy operational reality.
While current efforts are wisely focused on deterministic context – schema relationships, infrastructure mapping, dependency awareness, static analysis, and topology understanding – the long-term trajectory points toward incorporating runtime observability and operational signals. Infrastructure awareness isn’t just about what the code says; it’s about what the system is actually doing.
The next generation of AI assistants won’t just understand source code. They’ll need to understand runtime behavior, operational state, infrastructure drift, deployment realities, and the constantly shifting relationships within a system. Because production isn’t a static architecture diagram; it’s a perpetually moving target, a proof to engineering optimism held together by code and sheer will.
Why Does This Matter for Developers?
This disconnect has tangible implications for developers. Imagine an AI-powered debugging tool that confidently tells you a component is available and healthy based on its configuration, only for you to find out it was manually scaled down hours ago due to an unrelated issue. Or an AI suggesting a refactor based on an outdated dependency graph, leading to more problems than it solves. The danger isn’t incompetence; it’s a dangerous form of confidence derived from incomplete, outdated data. This pushes the burden of runtime validation back onto the human operator, negating some of the very benefits we expect from AI.
For developers, this means that AI tools, while promising, will likely require a heightened degree of human oversight and validation for some time. Relying solely on AI-generated insights for critical infrastructure decisions without understanding the underlying assumptions about system state could lead to significant operational missteps.
🧬 Related Insights
- Read more: AI Agents Talking: The Multi-Agent Orchestration Play
- Read more: DeFiLlama’s Blind Spots: 5 APIs That Deliver What It Can’t
Frequently Asked Questions
What is infrastructure drift? Infrastructure drift occurs when the actual state of your deployed infrastructure diverges from its declared or intended state, often due to manual changes, temporary workarounds, or failed automated updates.
Will AI replace infrastructure engineers? It’s unlikely that AI will entirely replace infrastructure engineers. Instead, AI is expected to augment their capabilities, automating routine tasks and providing insights, but human oversight, critical thinking, and complex problem-solving will remain essential, especially in understanding dynamic runtime environments.
How can AI better understand infrastructure reality? AI needs access to real-time runtime data, logs, monitoring alerts, and deployment reconciliation status, in addition to static code and configuration. Integrating these live operational signals will allow AI to build a more accurate model of the actual system state.