A thousand layers deep, the signal begins to fray. The raw essence of the input, once crisp and clear, starts to blur, dissolving into the complex computations of self-attention and feed-forward networks. This is the ghost in the machine, the data degradation that has haunted deep learning for years. But then, a revelation—or rather, a borrowed brilliance from another field entirely.
And here’s the thing: it’s not about a quantum leap; it’s about adding a stepping stone. This fundamental architectural choice, the humble Residual Connection, is doing for AI what sprint cycles are doing for software. It’s the secret sauce behind Transformer models’ incredible ability to scale, and it’s a philosophy we’ve already embraced in the world of high-performing teams.
Think of it this way. Imagine trying to teach a child calculus before they understand basic arithmetic. Utter madness, right? That’s what happens without these architectural bridges. Each layer in a naive neural network is forced to re-learn everything from scratch. It’s like building a skyscraper and, for every new floor, demolishing the base and starting over. Inefficient? Catastrophic, usually.
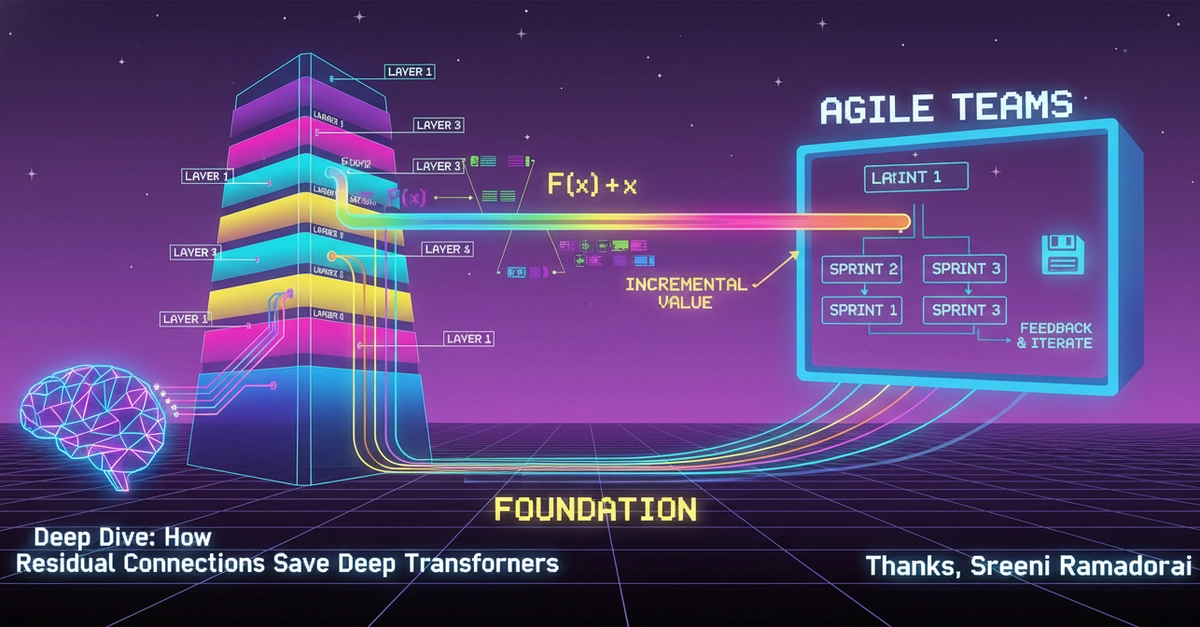
But Residual Connections? They’re like an express elevator for information. Instead of forcing a layer to map the entire problem space $H(x)$, it only has to learn the difference—the delta, the $F(x)$ that represents the new insights. The original input, $x$, is simply added back in. The output isn’t a wholly new creation; it’s the old foundation with a fresh coat of paint and a new wing.
This elegant mathematical trick—$H(x) = F(x) + x$—unleashes two superpowers for AI. First, Unobstructed Gradient Flow. During the critical training phase, when the AI learns from its mistakes via backpropagation, the gradients (those tiny signals telling the AI how to adjust) can zoom through these skip connections. They bypass the potentially flattening or vanishing effects of the intermediate layers. This allows us to train models that are not just dozens, but hundreds, even thousands of layers deep, a feat that was practically impossible before.
Second, Feature Preservation. The original input’s core meaning doesn’t get lost in translation. Those crucial semantic cues established early on remain intact, like a bedrock principle that isn’t eroded by later complexities. It’s the difference between a student truly understanding a concept and just memorizing answers.
Now, zoom out and look at your favorite Agile teams. What are they doing? They’re not waiting for the mythical “Grand Plan” release that arrives after years of silent, monolithic development. No. They’re shipping value incrementally, sprint by sprint. They build a core product, then iterate. They add a feature, gather feedback, refine. They preserve the stable application baseline while delivering new functionality.
It’s the same dance! The AI layer computes incremental feature adjustments ($F(x)$) while maintaining the input foundation ($x$); the Agile sprint delivers incremental feature updates while maintaining the stable application baseline. The residual connections ensure deep networks don’t lose their identity or variance—just like Agile’s version control and MVP architecture ensure teams don’t lose sight of the core product value.
This isn’t just a neat analogy; it’s a fundamental insight into scaling complex systems. We’re no longer in an era of building everything from the ground up every single time. That’s an unsustainable, inefficient model, whether you’re training a multi-billion parameter AI or managing a software project.
The Layer vs. The Sprint
A neural network layer computes incremental feature adjustments ($F(x)$) while maintaining the input foundation ($x$); an Agile sprint delivers incremental feature updates while maintaining the stable application baseline.
The goal, for both, is clear: use previous successes to achieve sophisticated, strong outcomes faster and with dramatically less risk. It’s about building the foundation, protecting it fiercely, and then iterating with focused, incremental steps.
This isn’t just about efficiency; it’s about a new paradigm for building intelligence and software. We’re moving from monolithic, high-risk endeavors to a world of continuous, adaptable evolution. The raw power of AI, unlocked by principles we’ve already learned to master in software development, is truly awe-inspiring.
Why Does This Matter for Developers?
For developers, this parallel underscores a vital principle: don’t reinvent the wheel, especially when it comes to core functionality. When building new features or tackling complex problems, always consider how you can extend or build upon existing, stable components. This is the essence of good software engineering, and it’s precisely what makes modern AI models so potent. It means embracing modularity, protecting your foundational code, and planning for incremental enhancements rather than massive, disruptive overhauls. It’s about creating systems that can grow and adapt, just like the successful AI architectures they mirror.
Is This a Fundamental Platform Shift?
Absolutely. The ability of AI models to scale exponentially, driven by architectural designs like Residual Connections, signals a profound change. It’s not just about bigger models; it’s about a more sustainable, efficient, and strong way of building intelligence. This approach allows for continuous improvement and adaptation, much like how web applications evolved from static pages to dynamic, interactive platforms. AI is becoming an ever-more integrated, ever-more powerful platform, and its scaling mechanisms are key to that ascendancy.
🧬 Related Insights
- Read more: Grafana Assistant: AI Sees Your Infra First
- Read more: Cloudflare’s Agent Stack: Rebuilt Browser Run Aims for the Top
Frequently Asked Questions
What are residual connections in AI? Residual connections, or skip connections, are a technique in neural network architecture that allows the output of a layer to be added directly to the output of a later layer. This helps prevent information loss and vanishing gradients in deep networks.
How do Transformer models scale? Transformer models scale effectively due to their architectural design, particularly the use of Residual Connections. These connections enable the training of extremely deep networks without significant degradation of performance, allowing for massive increases in model size and capability.
What is the relationship between AI and Agile development? The relationship lies in their shared philosophy of incremental evolution. Both Transformer AI architectures and Agile software development teams achieve complex, scalable results by building upon existing foundations rather than starting from scratch with each iteration.



