How One Developer Built a Production Pedigree Tree in PostgreSQL—And Why Your Genealogy App Is Probably Broken
A breeder's app tracking 200 animals in 9 days. The secret? Understanding why adjacency lists beat nested sets, and why your duplicates aren't a bug—they're inbreeding.
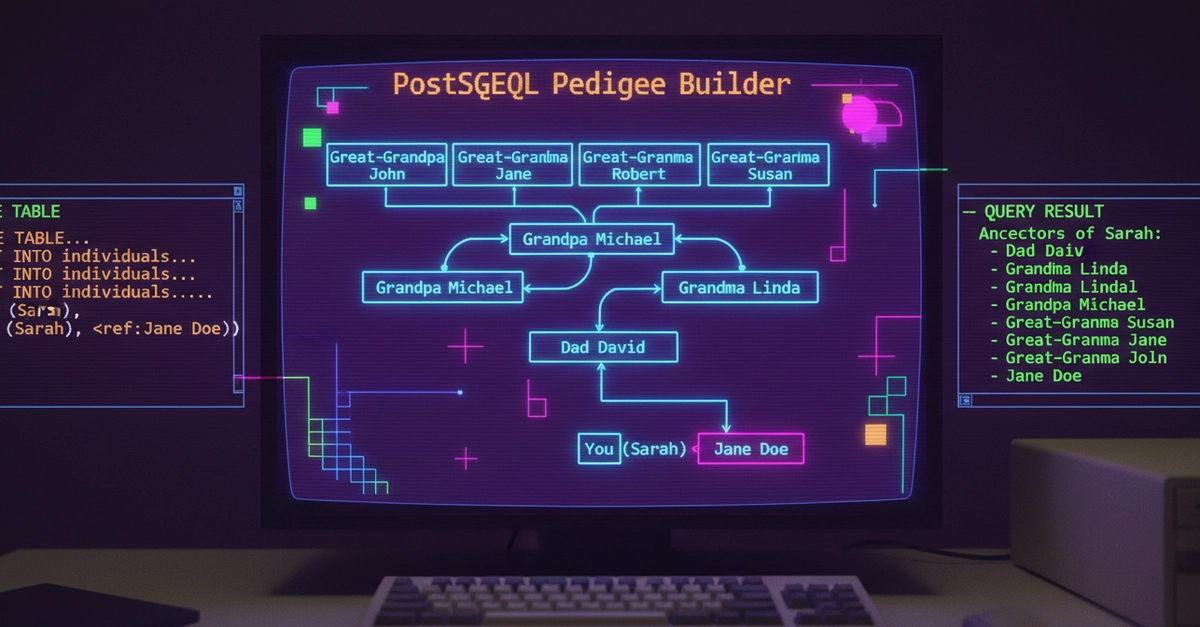
⚡ Key Takeaways
- Adjacency lists with self-referential foreign keys are the only schema that handles pedigrees correctly; nested sets and materialized paths fail at scale. 𝕏
- Recursive CTEs are the right tool for multi-generation ancestor traversal—they're elegant, performant, and standardized across SQL databases. 𝕏
- Duplicate ancestors in your pedigree query results aren't bugs; they're the signal for detecting inbreeding, and removing them corrupts your data. 𝕏
- Closure tables lose to recursive CTEs for pedigrees because common ancestors create path explosion—the exact scenario where you most need efficiency. 𝕏
Worth sharing?
Get the best Open Source stories of the week in your inbox — no noise, no spam.
Originally reported by Dev.to
Related Stories

Cloud & Databases
Claude Edges OpenAI in the 2026 Agent SDK Wars—Here's Why After Building Them All

Cloud & Databases
MLOps to LLMOps: Why AWS Teams Are Still Fumbling Production AI

Cloud & Databases
Stop Watching Tutorials: Your First Gemini API Project Takes 15 Minutes

Cloud & Databases