Word2Vec Didn't Count Words—It Predicted Them, and NLP Never Looked Back
Silicon Valley promised smart search with simple word counts. Word2Vec flipped the script—learning from context predictions—and suddenly machines 'got' king minus man plus woman equals queen. But who's really profiting?
⚡ Key Takeaways
Worth sharing?
Get the best Open Source stories of the week in your inbox — no noise, no spam.
Originally reported by Dev.to
Related Stories

Developer Tools
JSPrep Pro's RAG AI Engine: Fresh JS Interview Questions, No More Stale BS

AI & Machine Learning
AI Agents Gone Wild: The $400 Infinite Loop That Nearly Torched Our Budget
AI & Machine Learning
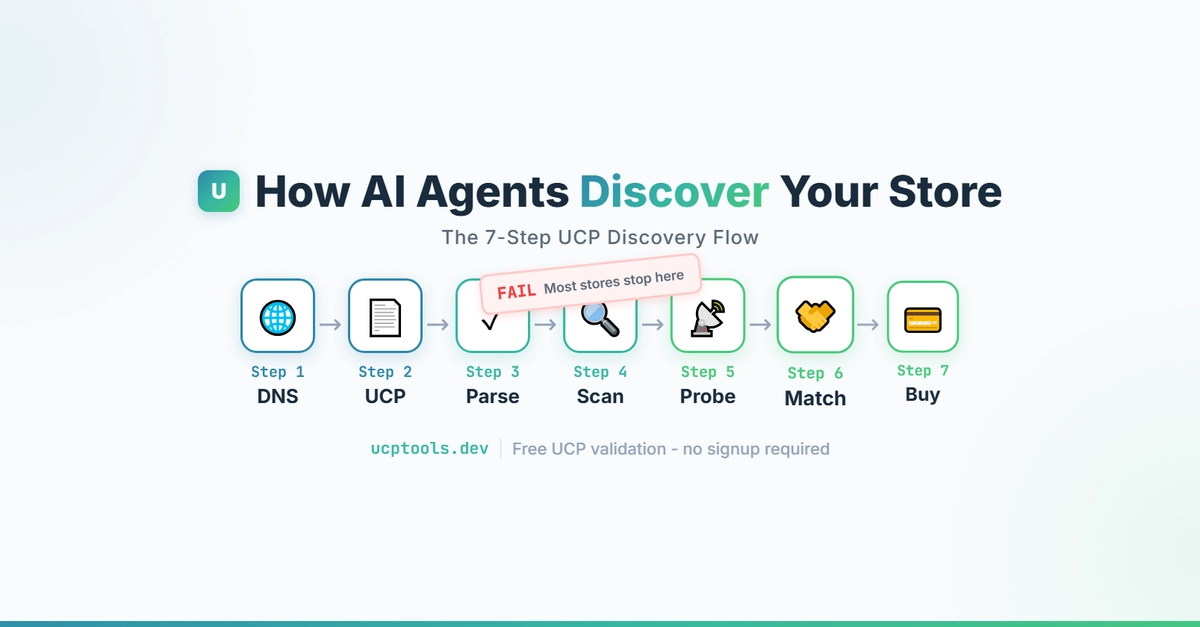
AI Shoppers Ignore Your Store Unless You Nail This 7-Step UCP Ritual

AI & Machine Learning