Here’s the thing: nobody was expecting CUDA 13.3 to drop with AI-generated CUDA kernels already demoing near-optimal performance for NVIDIA’s unreleased Blackwell architecture. The general expectation for a new CUDA release is usually incremental performance boosts and perhaps some new API surface area. Instead, NVIDIA’s latest toolkit lands alongside news that an AI system has already mastered writing what the developers are calling ‘speed-of-light’ CUDA kernels for Blackwell, effectively leapfrogging traditional manual optimization cycles. This isn’t just a software update; it’s a seismic shift in how GPU code might be developed going forward.
CUDA 13.3 Arrives: What’s Under the Hood?
So, NVIDIA has officially released CUDA Toolkit 13.3. This is the bread and butter for anyone pushing the limits of GPU computing, whether it’s crunching numbers for scientific simulations, rendering complex graphics, or, increasingly, training and running massive AI models. The release notes, which are always a deep dive for developers, are expected to detail a smorgasbord of performance improvements, new features, and critical bug fixes across the CUDA ecosystem. Think of it as the annual tune-up for the engine that powers much of our modern computational horsepower.
This toolkit isn’t just about making existing applications faster; it’s about enabling new frontiers. Developers rely on these updates to wring every last drop of performance from NVIDIA hardware. The continuous evolution of CUDA means that computational efficiency isn’t a static target; it’s a moving one, constantly being pushed forward by NVIDIA and the community.
The CUDA Toolkit is a foundational component for a wide range of high-performance applications, including AI, scientific computing, and graphics.
AI Takes the Wheel: Generating Blackwell Kernels
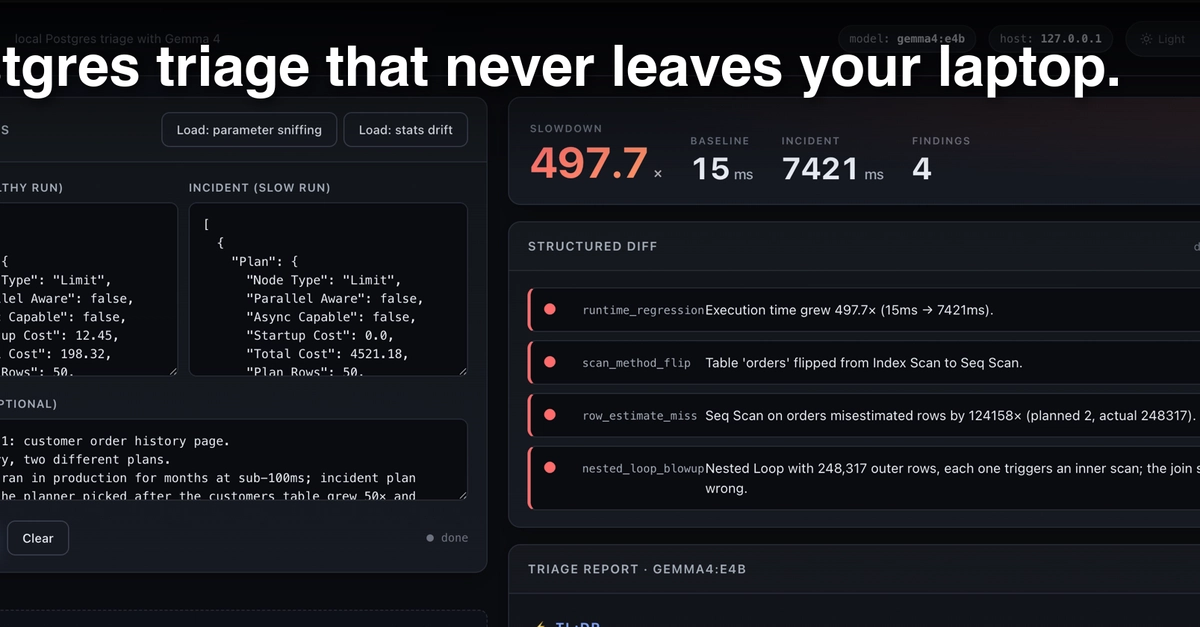
This is where things get truly interesting. A company called doubleAI has showcased an AI performance engineering system that can write CUDA kernels specifically for NVIDIA’s upcoming Blackwell architecture. And it’s not just writing them; it’s writing them well. They’ve achieved top performance on NVIDIA’s SOL-ExecBench benchmark, which is a serious feather in their cap. ‘Speed-of-light’ efficiency for GPU kernels is a bold claim, but if it holds up, it means this AI can produce code that’s as good as, or potentially better than, what human experts can painstakingly craft.
What does this mean practically? For starters, the manual grind of performance tuning for new GPU architectures—a process that can take months and involve highly specialized engineers—could be drastically compressed. Imagine rolling out support for a new NVIDIA chip not with months of hand-optimization, but with days or weeks of AI-driven kernel generation. This acceleration has profound implications for the pace of innovation in AI and High-Performance Computing (HPC). It democratizes high-performance code generation to some extent, allowing more developers to extract maximum potential from cutting-edge hardware.
FP4 for the Win: Shrinking LLM Memory Footprint
On the AI front, beyond the kernel generation, there’s another significant development: ThriftAttention. This technique tackles a persistent bottleneck in running large language models (LLMs) on GPUs: VRAM. The solution? Smart mixed-precision computing. Instead of using FP16 (half-precision) for everything, ThriftAttention judiciously applies FP16 to only the most critical parts of the attention mechanism. The bulk of the computational heavy lifting is done using FP4 (quarter-precision).
Why is this a big deal? FP4 offers a substantial reduction in memory usage compared to FP16, and consequently, FP32. This means LLMs can consume significantly less VRAM. For developers and researchers working with long-context models, where VRAM requirements balloon quickly, this is a game-changer. It promises to make much larger and more complex AI models feasible on hardware that might currently struggle. The goal is to achieve accuracy close to FP16 while reaping the VRAM and speed benefits of FP4. This optimization is crucial for driving down inference costs and enabling wider deployment of advanced AI.
It’s a clever bit of engineering that plays directly into the hardware limitations that often cap the scale of our AI ambitions. This FP4 approach could very well be the key to unlocking more powerful LLMs on consumer-grade hardware. NVIDIA’s continuous drive for performance, coupled with these innovative software techniques, paints a picture of an increasingly accessible and powerful AI future.
Is This AI Kernel Generation Sustainable?
The advent of AI systems capable of generating high-performance CUDA kernels, like the one demonstrated by doubleAI, raises a critical question about the long-term role of human GPU kernel developers. While the immediate impact suggests increased efficiency and faster hardware adoption, it also hints at a future where a significant portion of low-level optimization might be automated. However, complex, novel architectural features or highly specialized, domain-specific optimizations will likely still require human ingenuity for the foreseeable future. The AI acts as a powerful co-pilot, not necessarily a full replacement.
What Does FP4 Mean for AI Inference?
FP4 (quarter-precision floating-point) in AI inference primarily means a drastic reduction in the memory required to store model weights and intermediate activations. This translates directly into lower VRAM consumption on GPUs. For LLMs, this is particularly impactful as they tend to be memory-bound, especially when processing long sequences of text. By using FP4 for the less sensitive parts of the computation, developers can fit larger models into available VRAM, process longer contexts, and potentially achieve faster inference speeds due to reduced memory bandwidth requirements and increased computational throughput. The trade-off is typically a slight potential reduction in accuracy, though techniques like ThriftAttention aim to minimize this impact.